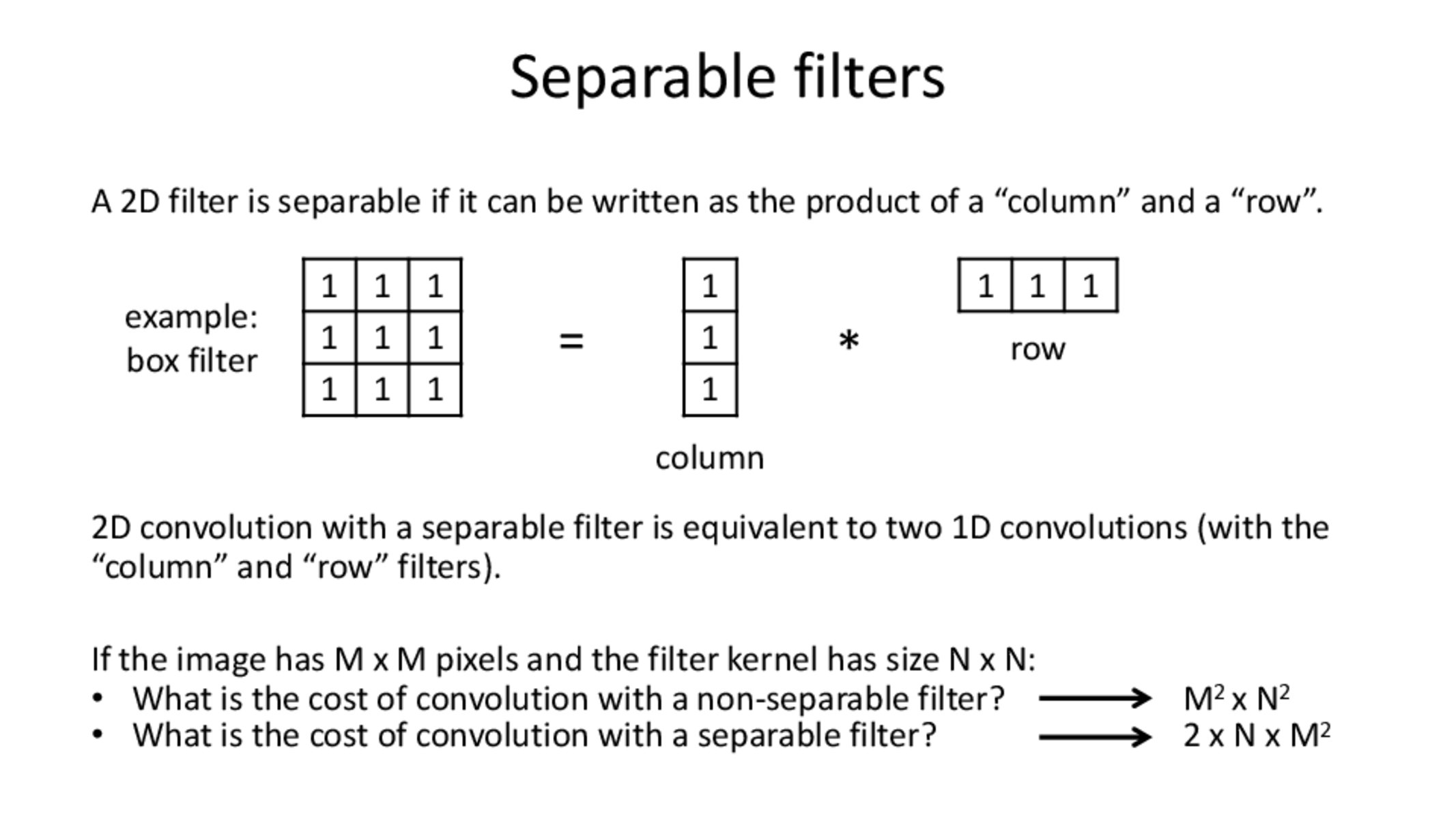
I'm not exactly sure why the cost of convolution for a separable filter is less than that of a non-separable. If I understand this correctly, a non-separable filter would have to be applied to every pixel in the image (so M^2 cost) and then for each pixel, n^2 operations are performed (to get the value at that specific pixel of the kernel) to linearly combine all the stuff in the kernel. But I don't get why a separable filter would be cheaper; wouldn't we still have to a filter to each pixel (so M^2 cost again) but then at each pixel we do N operations by applying a column convolution, and then another N operations by applying the row operations?
I think the main thing I'm confused about is how separable convolutions are applied to each pixel.
mpotoole
@qryy Applying the separable filter can be done in two separate 1D convolution operations, applied in series.
Suppose we are applying the discrete 2D convolution operation defined on this slide:
h[m,n] = sum_{k,l} g[k,l] f[m-k,n-l]
If the filter g is separable, it means that we can rewrite this equation as follows:
h[m,n] = sum_{k,l} gx[k] gy[l] f[m-k,n-l]
where gx and gy represent the 1D kernels of our separable 2D kernel g. We can then change the order of operations as follows:
h[m,n] = sum_{k} gx[k] (sum_{l} gy[l] f[m-k,n-l])
Here, we have two separate 1D convolution operations, applied one after the other. The first convolution operation requires M^2 N operations, and we can store its result. The second convolution operation applied to the result requires an additional M^2 N operations. The total number of operations is therefore 2 M^2 N.
I'm not exactly sure why the cost of convolution for a separable filter is less than that of a non-separable. If I understand this correctly, a non-separable filter would have to be applied to every pixel in the image (so M^2 cost) and then for each pixel, n^2 operations are performed (to get the value at that specific pixel of the kernel) to linearly combine all the stuff in the kernel. But I don't get why a separable filter would be cheaper; wouldn't we still have to a filter to each pixel (so M^2 cost again) but then at each pixel we do N operations by applying a column convolution, and then another N operations by applying the row operations?
I think the main thing I'm confused about is how separable convolutions are applied to each pixel.
@qryy Applying the separable filter can be done in two separate 1D convolution operations, applied in series.
Suppose we are applying the discrete 2D convolution operation defined on this slide:
h[m,n] = sum_{k,l} g[k,l] f[m-k,n-l]
If the filter g is separable, it means that we can rewrite this equation as follows:
h[m,n] = sum_{k,l} gx[k] gy[l] f[m-k,n-l]
where gx and gy represent the 1D kernels of our separable 2D kernel g. We can then change the order of operations as follows:
h[m,n] = sum_{k} gx[k] (sum_{l} gy[l] f[m-k,n-l])
Here, we have two separate 1D convolution operations, applied one after the other. The first convolution operation requires M^2 N operations, and we can store its result. The second convolution operation applied to the result requires an additional M^2 N operations. The total number of operations is therefore 2 M^2 N.