I'm a little confused on what in this slide comes from the dictionary, and what comes from the data point we are trying to analyze. Can someone please go over what is known vs what is gotten from the data point?
motoole2
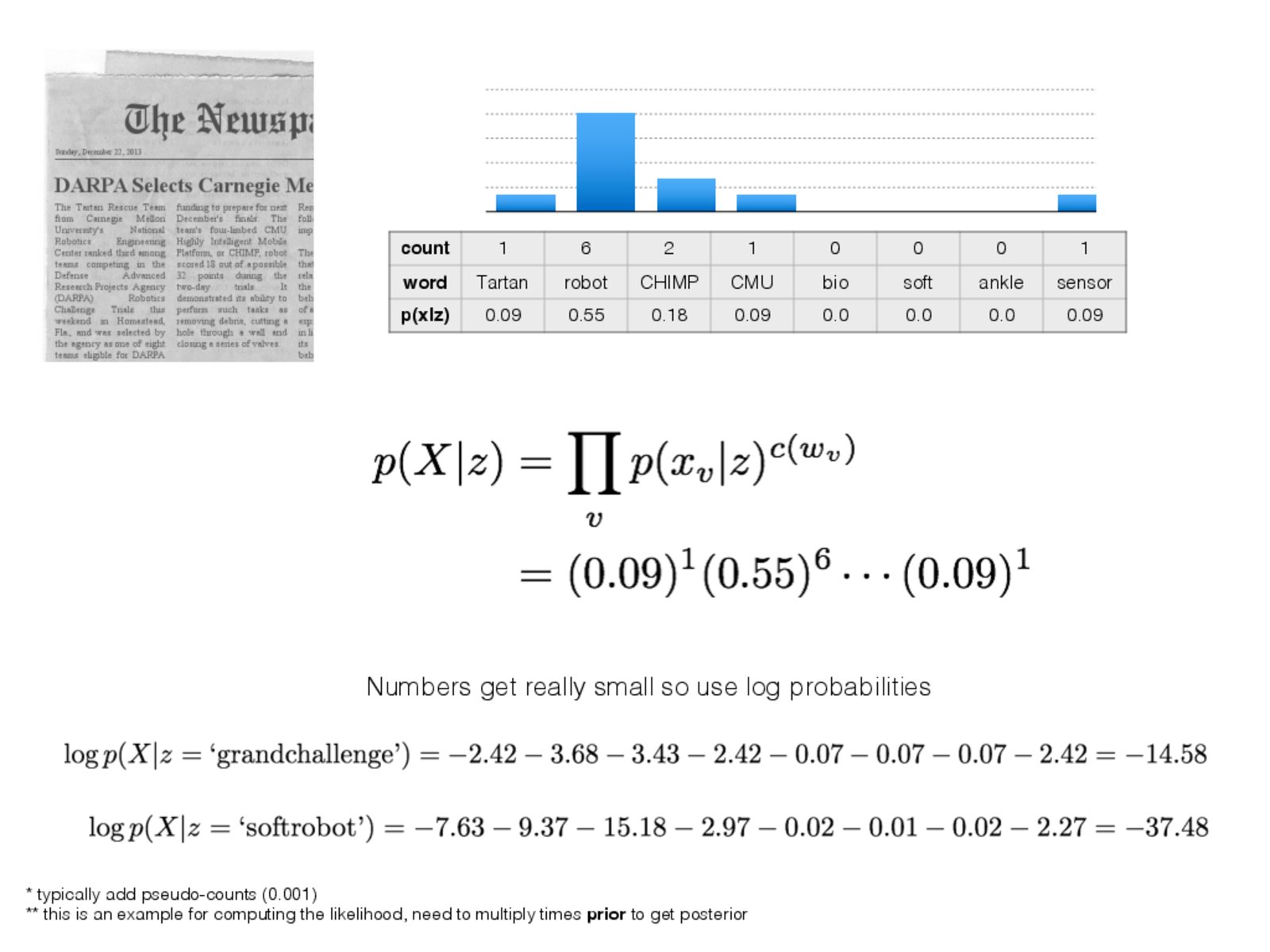
Sure. As stated in this slide, the standard Bag of Words pipeline consists of three steps: (i) dictionary learning, (ii) the encoding step, and (iii) the classification step.
(i) Our dictionary is computed in advance, and consists of literal words: "Tartan", "robot", "CHIMP", "CMU", "bio", "soft", "ankle", and "sensor".
(ii) The encoding step involves counting the occurrences of these words in article to create a Bag of Words vector. For example, Tartan appears 1 time, robot appears 6 times, etc.
(iii) We now need to classify this article. This involves two steps:
We need to "learn" a likelihood function, p(X | z), that provides the likelihood of observing the Bag of Words vector X for the given class z. For example, for "grandchallenge", the likelihood of observing the word "Tartan" is quite small. We use the articles in our training data to compute this likelihood function.
At test time, we can simply use our pre-computed likelihood function to evaluate log probabilities for new articles. In this case, X is given from step (ii), and the likelihood function p(X | z) is precomputed based on our training set. That way, we can evaluate p(X | z) for all discrete labels z at test time to compute the most likely label.
ADog
Thank you for the explanation!
As a follow up, is each p(x_v|z) precomputed by simply counting the number of instances of x_v across all training data of class z, and then dividing it by the number of total features in all training data of class z?
motoole2
Yes---that's exactly how these probabilities were computed in this case. Note that the sum of p(x_v | z) for all words in your dictionary equals to 1.
I'm a little confused on what in this slide comes from the dictionary, and what comes from the data point we are trying to analyze. Can someone please go over what is known vs what is gotten from the data point?
Sure. As stated in this slide, the standard Bag of Words pipeline consists of three steps: (i) dictionary learning, (ii) the encoding step, and (iii) the classification step.
(i) Our dictionary is computed in advance, and consists of literal words: "Tartan", "robot", "CHIMP", "CMU", "bio", "soft", "ankle", and "sensor".
(ii) The encoding step involves counting the occurrences of these words in article to create a Bag of Words vector. For example, Tartan appears 1 time, robot appears 6 times, etc.
(iii) We now need to classify this article. This involves two steps:
We need to "learn" a likelihood function, p(X | z), that provides the likelihood of observing the Bag of Words vector X for the given class z. For example, for "grandchallenge", the likelihood of observing the word "Tartan" is quite small. We use the articles in our training data to compute this likelihood function.
At test time, we can simply use our pre-computed likelihood function to evaluate log probabilities for new articles. In this case, X is given from step (ii), and the likelihood function p(X | z) is precomputed based on our training set. That way, we can evaluate p(X | z) for all discrete labels z at test time to compute the most likely label.
Thank you for the explanation!
As a follow up, is each p(x_v|z) precomputed by simply counting the number of instances of x_v across all training data of class z, and then dividing it by the number of total features in all training data of class z?
Yes---that's exactly how these probabilities were computed in this case. Note that the sum of p(x_v | z) for all words in your dictionary equals to 1.