Why can $\frac{\partial W}{\partial p}$ be precomputed? It seems like it needed to be calculated in each iteration in the additive alignment case.
motoole2
Because it is independent of the warp parameters p. It is the gradient of $T$ evaluated with respect to $W(x;p)$ where $p=0$, i.e., it is simply the gradient of $T$ with respect to $W(x;0) = x$.
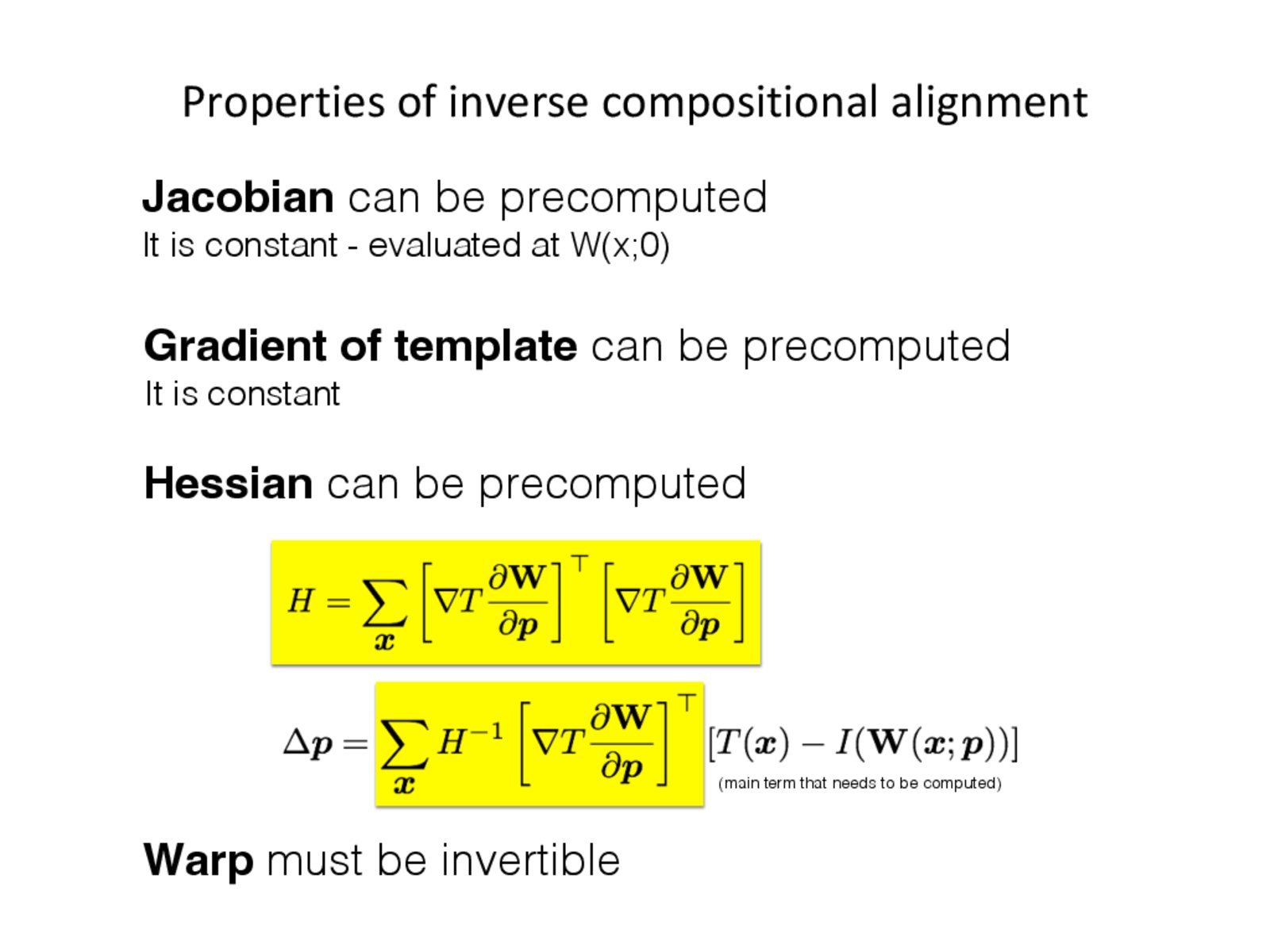
Why can $\frac{\partial W}{\partial p}$ be precomputed? It seems like it needed to be calculated in each iteration in the additive alignment case.
Because it is independent of the warp parameters p. It is the gradient of $T$ evaluated with respect to $W(x;p)$ where $p=0$, i.e., it is simply the gradient of $T$ with respect to $W(x;0) = x$.