why we need activation function? Whats the difference bewteen different activation functions?
motoole2
Good question. It's actually essential for the perceptron to do anything interesting.
Consider the case where you're dealing with a MLP (multi-layer perceptron) where the activation functions are linear. That is, the output of a particular layer can be written in matrix form: $y = W x$, where the vector $x$ of length N is the input, the vector $y$ of length M is the output of M perceptrons, and $W$ is a matrix of weights. One row from the matrix $W$ corresponds to the weights used in one perceptron.
Now, if we were to stack multiple $K$ layers together, the result of your MLP would be $y = W^K W^{K-1} \cdots W^2 W^1 x$, which can be simplified as $y = \hat{W} x$. In other words, irrespective of the number of layers used, you would end up with a linear function for your perceptron!
The activation functions are therefore essential to avoid this from happening.
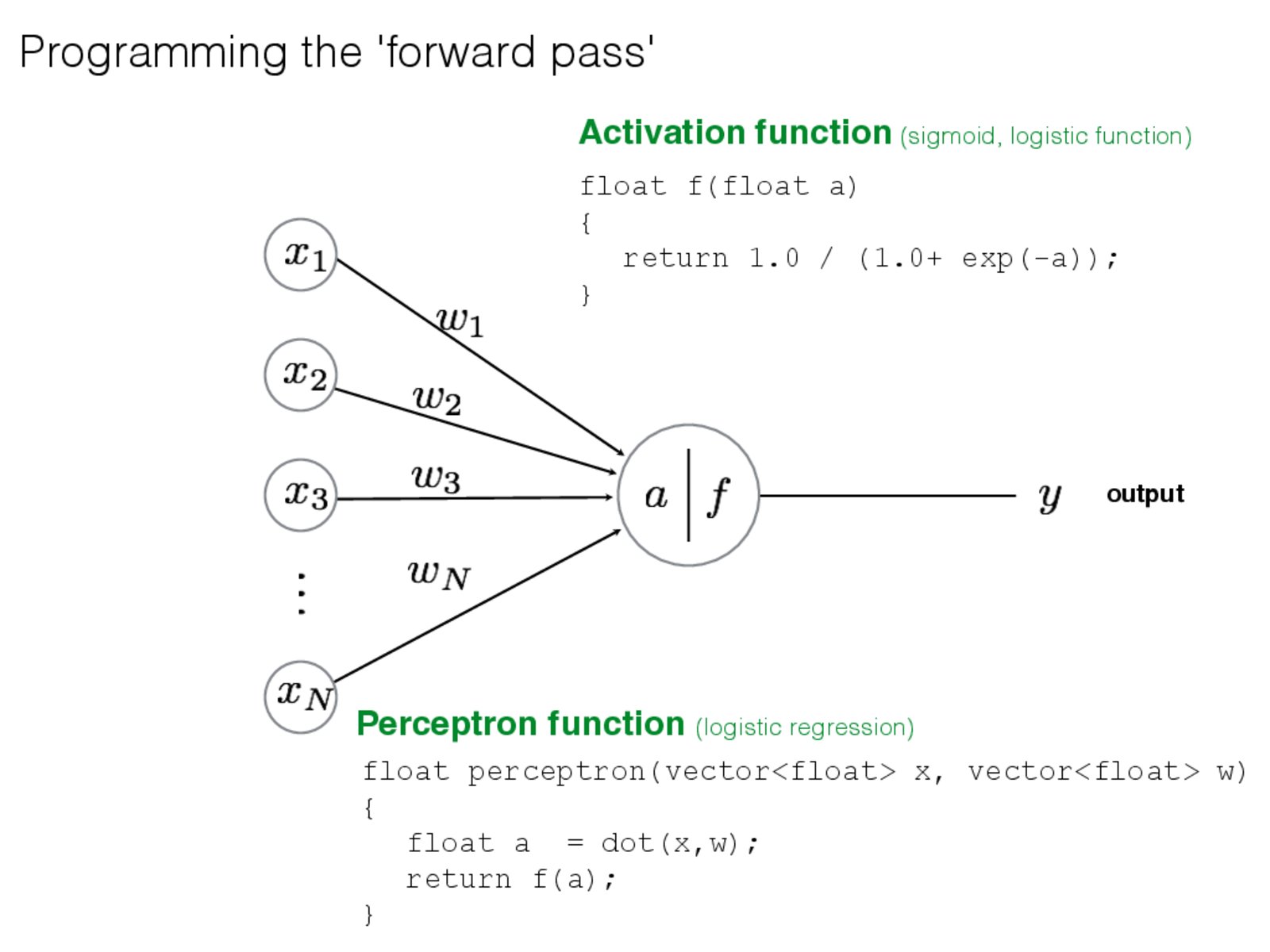
why we need activation function? Whats the difference bewteen different activation functions?
Good question. It's actually essential for the perceptron to do anything interesting.
Consider the case where you're dealing with a MLP (multi-layer perceptron) where the activation functions are linear. That is, the output of a particular layer can be written in matrix form: $y = W x$, where the vector $x$ of length N is the input, the vector $y$ of length M is the output of M perceptrons, and $W$ is a matrix of weights. One row from the matrix $W$ corresponds to the weights used in one perceptron.
Now, if we were to stack multiple $K$ layers together, the result of your MLP would be $y = W^K W^{K-1} \cdots W^2 W^1 x$, which can be simplified as $y = \hat{W} x$. In other words, irrespective of the number of layers used, you would end up with a linear function for your perceptron!
The activation functions are therefore essential to avoid this from happening.